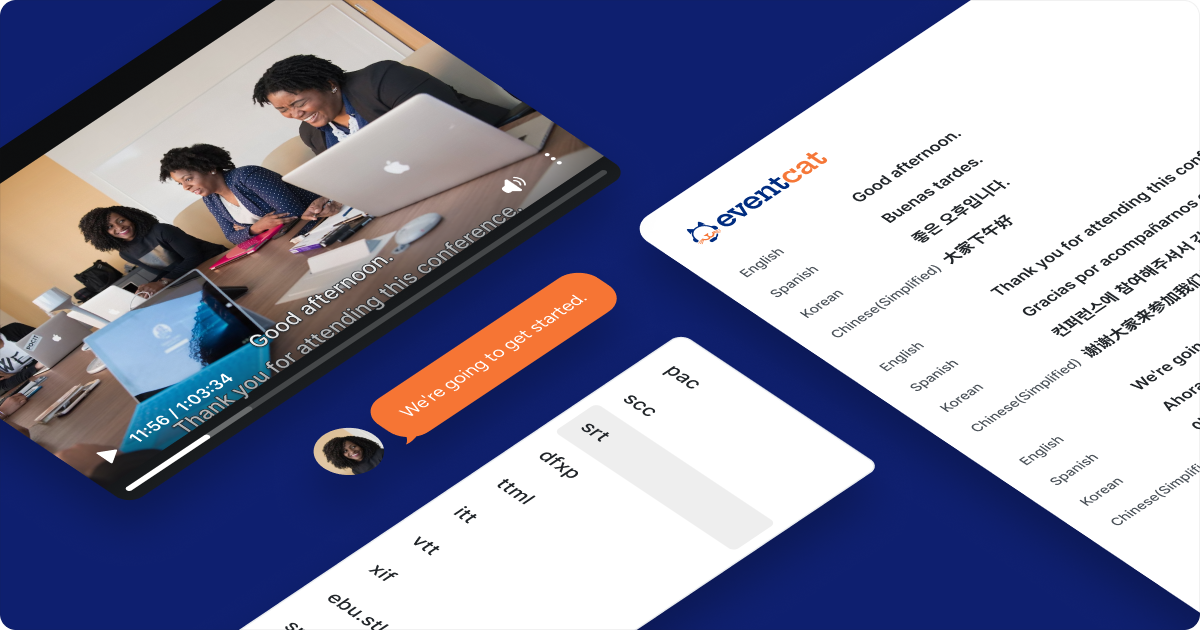
Beyond Automatic Transcription: Leveraging Speaker Diarization for MediaCAT’s Auto Transcription Tool
In the world of content localization, efficiency and accuracy are paramount. MediaCAT's speaker diarization feature is designed to address these needs head-on. Let's explore what speaker diarization is, why it matters, and how MediaCAT implements this technology to enhance your localization workflow.
Understanding Speaker Diarization
Speaker diarization is a process that labels different speakers within an audio or video file, distinguishing between who spoke when. This technology is particularly valuable in various fields, including legal transcription, podcast production, and broadcast media.
The Impact of Speaker Diarization on Localization:
- Time-Saving Efficiency: By automatically labeling speakers, MediaCAT's speaker diarization feature significantly reduces the time spent on manual speaker identification. This means less rewinding and re-listening to audio tracks, allowing editors to focus on refining the content.
- Improved Transcription Accuracy: Well-identified speaker information guides our engine in making better judgments about line breaks during auto-transcription, resulting in more accurate initial transcripts.
- Flexible Subtitle Creation: Users can choose to include or exclude speaker names in subtitles, offering versatility in deliverable formats.
- Enhanced Accessibility: For hearing impaired viewers, knowing who is speaking at any given moment greatly improves content comprehension.
- Content Searchability: Speaker identification enables efficient indexing of audio content, making it easier to locate specific segments spoken by particular individuals within large datasets.
MediaCAT's Speaker Diarization Offerings
MediaCAT offers two levels of speaker diarization to cater to different project needs and content types. The standard speaker diarization is automatically applied to all media content transcribed through MediaCAT's 'Sync' feature. This base-level service requires no additional processing time or extra steps from the user. It utilizes audio information to identify and label speakers, providing an efficient solution for shorter content or projects where quick processing is a priority.
For projects demanding higher precision, MediaCAT has introduced Enhanced Speaker Diarization (ESD). This advanced feature is designed to achieve superior accuracy by utilizing both audio and visual cues for speaker identification. ESD can achieve up to 91% accuracy in speaker diarization, offering higher precision for non-animated programs longer than 15 minutes.
For more information on Enhanced Speaker Diarization, check out Audio-visual Speaker Diarization for Media (Multimodality)https://www.xl8.ai/blog/audio-visual-speaker-diarization-for-media-multimodality
How to Use Speaker Diarization in MediaCAT
Using speaker diarization in MediaCAT is straightforward. For standard diarization, users simply need to upload their media files to MediaCAT and initiate the 'Sync' process. The speaker diarization is automatically applied without any additional steps or input required from the user.
To leverage the Enhanced Speaker Diarization (ESD) feature, users can activate it when creating a Sync project in MediaCAT. In the Sync Option menu, there's a toggle for 'Enhanced Speaker Diarization'. Activating this option initiates the advanced audio-visual analysis, providing improved speaker identification for your content.
By incorporating speaker diarization into your localization workflow with MediaCAT, you can expect improved efficiency, accuracy, and flexibility in your projects. This feature not only saves time but also enhances the overall quality of your localized content, making it more accessible and user-friendly.
As the demand for quick, accurate content localization continues to grow, tools like speaker diarization become increasingly valuable. MediaCAT is committed to providing cutting-edge solutions that address real-world challenges in the localization industry, helping you deliver high-quality content efficiently and effectively.